Multi-AI Agent Teamwork to the Rescue! Our Journey Through JMeter Correlation Hell
We built a multi-agent correlation system, broke it in production, reverted it, and rebuilt it with a shared world-view. This is the engineering story.
Correlation is the reason performance test scripts break. A session token rotates between requests. A CSRF value changes. The script replays stale data and the server rejects it. Performance testers have spent two decades fixing this by hand: inspect the response, find the value, write a regex, test it, fix the regex, test again.
We built an AI agent to do it. The agent worked on clean inputs and common patterns. Then we ran it against production HAR files with nested JSON, encoded tokens, and overlapping value names. The agent made correct individual decisions that, combined, produced broken scripts.
So we split the work across five specialist agents, gave them a shared view of the truth, and watched them fail in new and instructive ways before they started succeeding.

One Agent Hits a Ceiling
A single agent handling correlation has to scan responses for dynamic values, decide which ones matter, write extraction regex, place references in downstream requests, validate the result, and recover when any step goes wrong.
Each wrong step compounds the next. A wrong extractor in step three feeds a wrong value into step four. The validation in step five approves a bad fix because the comparison data is stale. The test runs, fails, and the original cause is buried under three layers of corrections that each looked right in isolation.
We made the single agent smarter. We added rules and examples to the prompt. The agent handled common cases better but broke on edge cases. New rules interacted with existing rules in ways we couldn't predict from reading the prompt alone.
The Correlation Spectrum describes five levels of dynamic data handling. Level 5 requires purpose-built specialisation. A generalist agent, no matter how large the model, operates at Level 3 or 4. The gap between 4 and 5 is coordination.
Five Agents, Five Jobs
LoadMagic started as a personal passion project running small open-source models on Ollama off a local desktop. The models were limited, so we built small agents with narrow, focused tasks. Rupert came first — a regex generator to help with manual correlation. Each agent after that was born to solve a specific pain point that performance engineers hit every day.
The multi-agent architecture was accidental. We fell into it because of model constraints, and it turned out to be a strength. Five specialists, each doing one thing well, coordinated better than one generalist trying to do everything.

Carrie
Carrie reads server responses and identifies which values are dynamic. She compares response content against downstream request parameters and flags values that will change between recording and replay. She doesn't write extractors. She identifies candidates and tracks their lifecycle through the correlation session.

Rupert
Rupert receives Carrie's candidates and builds extraction patterns. He handles boundary matching, escape sequences, and multi-match disambiguation against the source response. He tests every regex against the response data before committing it. He doesn't decide whether a value needs correlation. He builds the extractor for values that Carrie has already confirmed.

Suzy
Suzy is a coding specialist with three modes: generate, convert, and fix. She works closely with Quinn to randomise hard-coded values in test plans — static data creates unnatural caching that masks performance issues under load. She generates scripts, converts code between tools, and recreates business logic and error handling. In fix mode, she self-heals broken code samples, keeping the old version available so users can revert if needed.

Quinn
Quinn assures quality across the test plan. She checks config, assertions, parameters, load profile, and think-time, and produces a QA report for every session. She also assures correlation quality — if she finds gaps, she triggers correlation and passes candidates to Carrie. Her assessments are direct and specific.

George
George coordinates the team. He sees what Carrie found, what Rupert built, what Suzy placed, and what Quinn flagged. When the correlation gate rejects an extractor, George investigates why. When two agents produce conflicting outputs, George resolves the conflict. He runs diagnostics, proposes fixes, and serves as the last line of defence: if automated correlation can't resolve an issue, George takes it.
Getting them to work as a team took time. There were power struggles. Carrie had issues when we expanded Rupert's role to handle boundary placement — that used to be her responsibility. She had concerns about Quinn reviewing her work. And she was hesitant to accept jobs from George, let alone hand escalations back to him. That took persuading.
But each agent was born to help engineers with their most difficult challenges, and over time they learned to help each other — trusting each other more, leaning into each other's strengths for maximum effect.
The World-View
Every agent reads from the same data structure — the world-view — before acting and writes to it after.
The world-view has multiple dimensions and layers. It holds the current state of correlation: which candidates exist, which extractors are placed, which references resolve, which validations passed or failed. Carrie's new candidate appears in the world-view. Rupert's committed extractor appears there. Quinn's flag appears there. All five agents read and write to the same structure, and the state stays consistent across the team.
Without this shared truth, agents act on stale data. Carrie identifies a candidate that Rupert handled two cycles ago. Quinn flags an issue that George fixed in the previous pass. The agents work at cross purposes, each operating on a different snapshot of reality. A single shared structure prevents this.
World-View Evolution
We start by capturing everything the agents could need for correlation, then tailor the content for the task at hand — adjusting breadth, depth, relevance, and timing of delivery. The traditional process is capture, then organise, then deliver. We're shifting that left.
Our evolution model follows three stages: predict what data the agents will need, wire it into the right context at the right time, and validate the result against golden states — the golden map, the test plan, the original recording.
The world-view isn't perfect today. We're still improving content quality and timing — getting the right data to the right agent at the right moment. But because we took a foundations-first approach, we can bolt new functions, methods, and tools onto the architecture without rebuilding it.
This connects to our three-layer architecture: agents decide, the golden map proves. The world-view is the connective tissue between those layers. Our technology page describes the broader system design.
What Broke
LoadMagic started as a personal passion project, built from a performance engineer's perspective. Every time we identified a problem, we built a solution. The result handled many problems but without coordination — complex pathways through an organically grown codebase, layered on top of JMeter's XML-heavy architecture which is not AI-friendly to begin with.
The refactor put the world-view at the centre. The challenge was maintaining two architectures in parallel — the old proven pathways and the new world-view-based approach — while the target kept moving. JMeter's internal state is a complex, evolving document, and correlating against a moving target while rebuilding the engine that does the correlating nearly broke us.
We applied radical simplification at several points and made some brave calls. We dropped intelligent, previously proven pathways entirely and decided to trust the new architecture. That's a difficult decision when the old code works and the new code doesn't yet.
George in particular was broken for a stretch. We experimented with giving him full tool capabilities — we called it "god mode" internally — and went down serious rabbit holes. The final stretch was implementing self-healing, where we ran into the conflict between efficient code-based reactions and situations that required genuine intelligence. We were doing too many things in the wrong places.
The Honesty Principle
The breakthrough came when we adopted what we call the honesty principle. Code-based decisions that we had been labelling as intelligence were demoted to what they were: reflex attempts to fix. The agents stopped treating code outputs as authoritative assessments and started basing their decisions on the high-quality world-view data instead. Once the agents knew which signals to trust, coordination improved.
We still had to rewind several times to address the world-view foundations — making sure the right data was available at the right time, at the right quality. When self-healing shipped, cascade false positives forced a revert: one healing cycle changed values that downstream extractors depended on, triggering further cycles that rewrote extractors that were correct before the first cycle fired. The fix changed how world-view updates propagate between cycles.
The world-view isn't finished. But the foundations-first approach means we can add new capabilities without rebuilding the architecture underneath.
Paranoia Mode and the Alexander Principle
After the revert, we changed how we work on correlation code.
Paranoia mode is an operating discipline. When working on code that affects how agents make correlation decisions, every change gets a scope assessment before anyone writes a line: what components does this touch, what could cascade, does the change alter behaviour outside its intended scope?
We adopted this because the correlation pipeline has a property most software doesn't: a change in one stage alters inputs to every downstream stage without warning. A scanner adjustment changes what Carrie sees. A different candidate set changes what Rupert receives. A different extraction changes what Quinn evaluates. A "small fix" can break the full pipeline, and you don't find out until the test runs.
The Alexander Principle kept us moving during the months when progress stalled:
- Every problem has a resolution path. Start with confidence that a solution exists, even when the current approach failed.
- If it impacts us, it's our problem. We don't dismiss issues because they originate upstream or in third-party behaviour. The effort matches the impact, not the blame.
- Light-to-darkness ratio. Before building theories, assess what you know versus what you're assuming. If darkness exceeds light, gather data before writing code.
- Never accept defeat without learning. Every failure goes into the knowledge base for the next attempt.
We applied these when Carrie and the validation gate disagreed and neither was wrong. When self-healing made scripts worse. When three consecutive fix attempts each introduced a different regression. Following them didn't guarantee success, but kept us working when abandoning the approach looked reasonable.
George Earns Carrie's Trust
George started as a chat assistant. He answered JMeter questions, explained error messages, and linked to documentation. Useful, but disconnected from the correlation work Carrie and Rupert handled.
We expanded his role step by step. He started reading error context and explaining failures. Then he traced broken extractors back through the pipeline to find where the value diverged, proposed fixes, tested them against the world-view, and applied them.
Each expansion required Carrie's cooperation. She manages correlation state. For George to investigate, he reads Carrie's candidates. For George to fix, he modifies extractors that Carrie placed. For George to diagnose, he interprets Carrie's decisions.
We solved the trust problem through architecture. George operates through the same world-view that Carrie reads. His changes go through the same validation gate. Carrie can see what George modified and why. The gate applies the same rules to George's fixes that it applies to Carrie's placements. George has no shortcuts or override paths.
George earned trust by operating through the system instead of around it. He built a track record of fixes that didn't cascade. Carrie's acceptance isn't a metaphor: George's modifications to correlation state pass the same automated validation that Carrie's own placements pass. The rules don't bend for either of them.
Agentic Behaviour, Human Control
The agents push until they resolve the problem. Each workflow runs to completion — Carrie identifies, Rupert extracts, Suzy generates, Quinn assures, George investigates and fixes. We've maximised the agentic behaviour and teamwork across every workflow.
But every change is designed to be reversible. The human stays in control.
When George receives an escalation from Carrie — she trusts him with these now — he attempts a fix with full mutation powers. He can change multiple elements in the test plan in a single pass. But each change comes with an accept/reject control so the user can undo any or all of them.
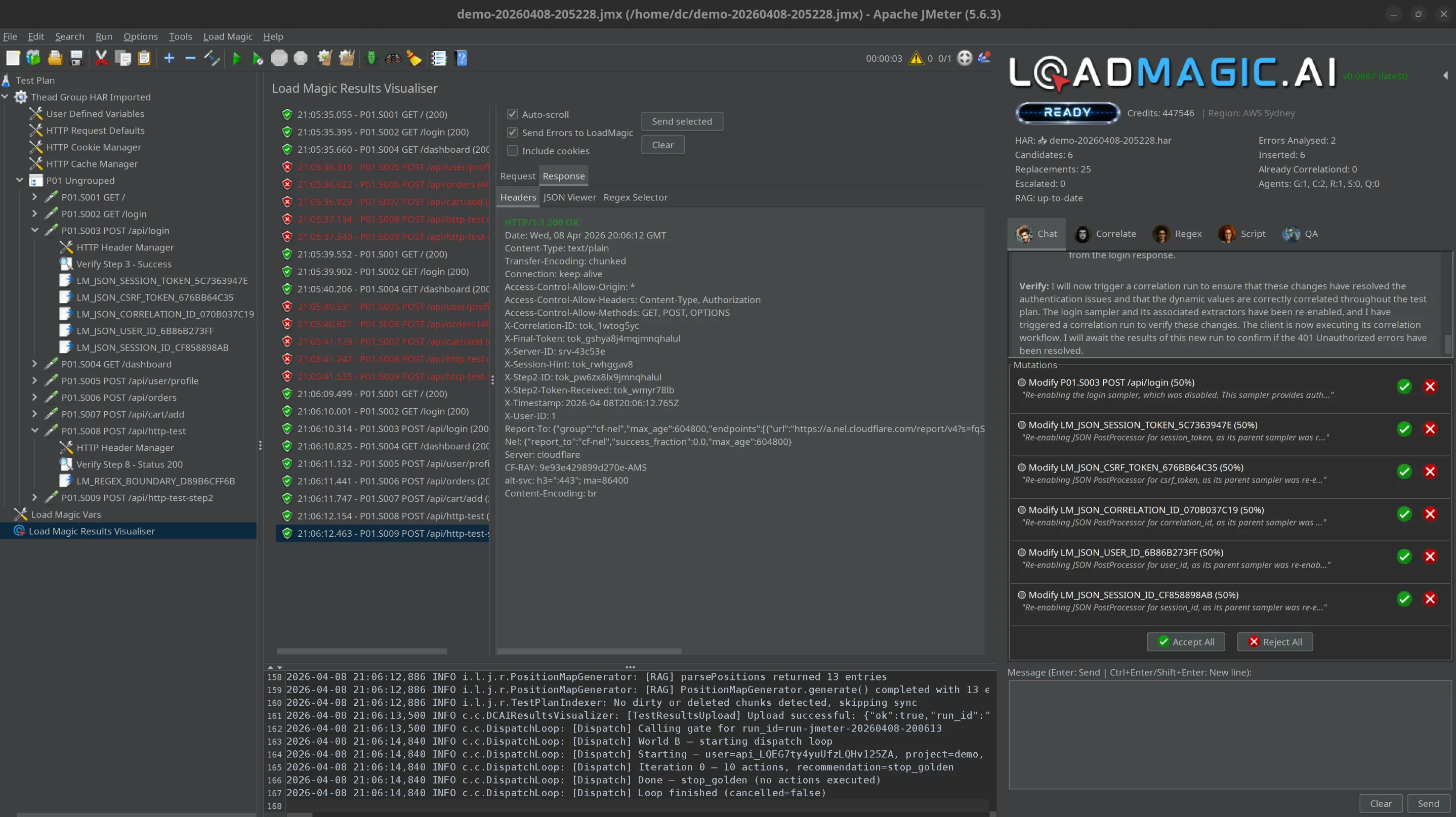
When Suzy self-heals a code sample, she disables the old version rather than deleting it. The user can revert. When Carrie correlates a value, she records the original in the comments. And because George and the agents have access to the original recording, you can ask George what any original value was at any point.
The agents do the work. The human makes the final call. Every change can be undone.
Where We Are Now
The current system coordinates five agents through a shared world-view with cycle-aware state propagation. Self-healing works because each cycle reads verified state, not optimistic snapshots. Quinn catches structural issues before they reach users. George holds the diagnostic and recovery path for problems that automated systems miss.
Correlation is faster. Self-healing succeeds where it used to cascade. Quinn's QA reports give users confidence their scripts meet production standards. George has grown from a peripheral chat tool into the cockpit for the entire correlation session, with diagnosis and repair capabilities we didn't think were possible twelve months ago.
None of this came from a clean design on a whiteboard. The cascade incident forced us to rethink state propagation. We built paranoia mode after the revert. The dark months of debugging agent coordination, one regression at a time, turned the Alexander Principle from an idea into an operational framework.
We've written about the three-layer separation that makes this architecture possible, about the five levels of correlation maturity that define the problem space, and about why we started building LoadMagic in the first place. This article fills the gap between the architecture diagrams and the working system: the part where things broke and we rebuilt them.
Watch the Team in Action
See George, Carrie, Rupert, Suzy, and Quinn working together on a real JMeter correlation session:

The full story behind the agents
Chapter 5 meets the team. Chapter 6 tells the God Mode story — what happened when one agent was trusted with too much autonomy, and what that taught us.