The Correlation Spectrum
Five approaches to dynamic data correlation in performance testing — from manual JMeter and Locust correlation to specialised AI-native performance engineering.
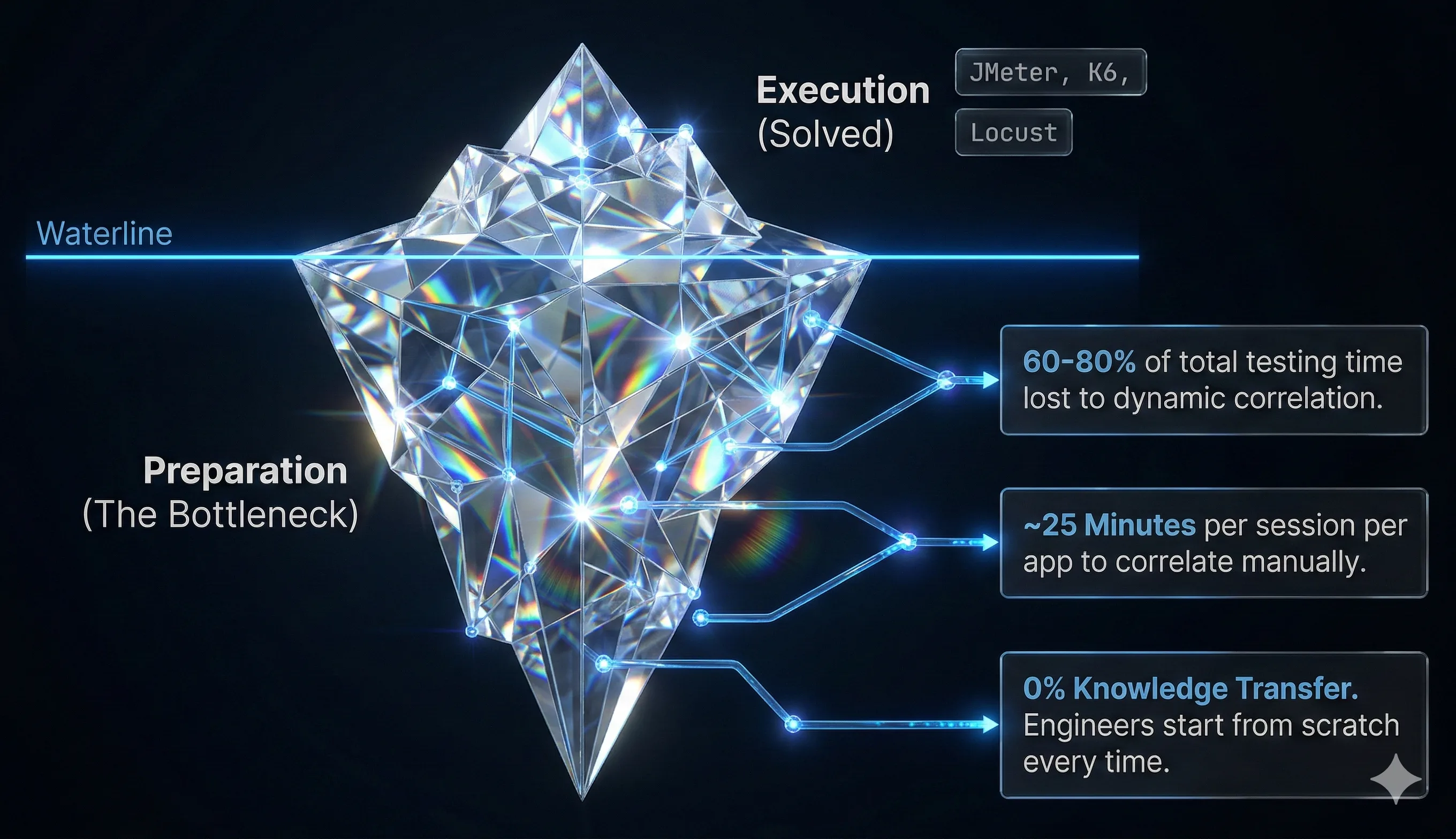
The Problem That Won't Go Away
Every performance tester knows the feeling. You record a user journey, hit replay, and watch your script crash within seconds. The culprit is almost always the same: dynamic data. Session tokens, CSRF values, authentication keys, timestamps, and transaction IDs all change between requests. If your script replays the values it recorded rather than extracting fresh ones from server responses, it's dead on arrival.
This process — identifying dynamic values, finding their origin in a previous server response, extracting them, and substituting them into subsequent requests — is called dynamic data correlation. It is, without exaggeration, the single most time-consuming and frustrating part of performance test preparation, whether you work in JMeter, Locust, or any other load testing tool. Industry surveys consistently rank it as the number one pain point. A simple script might need a handful of correlations. A complex enterprise application — think Salesforce, SAP, or a modern microservices checkout flow — can require dozens or even hundreds.
The industry has evolved multiple approaches to tackling this problem. They range from heavily manual processes through to fully autonomous, AI-native systems. Understanding the differences isn't just an academic exercise — choosing the right approach for your context directly determines whether your performance testing programme is viable, efficient, or simply too expensive to maintain.
This article walks through five distinct levels of correlation capability — a framework for understanding where your current JMeter, Locust, or other performance testing AI tooling sits, and what the next level of performance engineering looks like. Not every team needs the most advanced approach, and not every tool at the lower levels is without merit. The goal is to help you — whether you're an engineer choosing tooling, or a manager evaluating investment — understand what each level offers, where it breaks down, and what it costs in practice.
1Level 1: AI-Assisted Manual Correlation
What it looks like:
An engineer records a user journey, replays it, observes the failures, and manually identifies which values need correlating. The tooling provides some intelligence in the background — auto-complete suggestions, highlighting of likely dynamic values, perhaps basic pattern recognition — but the human drives every decision.
How it works in practice:
The engineer opens the recorded script, often containing hundreds of HTTP requests. They look at a failing request, compare the recorded response to the replayed response, spot a value that has changed, then manually search backward through prior responses to find where that value first appeared. They write an extraction rule (typically a regular expression or boundary-based extractor), insert it after the originating response, and replace the hardcoded value in the failing request with a variable reference.
Modern tools at this level may use lightweight AI to suggest "this looks dynamic" or to auto-generate a regex pattern once the engineer has identified the target. But the core workflow — the detective work of tracing where a value came from and deciding what to do about it — remains human-driven.
Where it works well:
This approach is perfectly viable for simple applications with a small number of dynamic values — perhaps five to ten correlations per script. APIs with straightforward token refresh flows, internal tools with basic session management, or applications where the tester is deeply familiar with the architecture all fall into this sweet spot. The manual approach also gives the engineer maximum control and visibility, which matters in regulated environments where every test artefact must be explainable.
Where it breaks down:
The problem is scale. Manual correlation effort doesn't grow linearly with complexity — it grows exponentially. Each additional dynamic value increases the search space and the likelihood of cascading errors, where fixing one correlation breaks another. Research suggests that for scripts with thirty or more correlation candidates, manual effort can consume forty or more hours per script. At that point, teams often abandon scripts rather than maintain them — a phenomenon sometimes called the "Script Museum," where test assets sit unused because they're too expensive to keep current.
Typical time investment: Minutes per correlation for simple cases. Hours per script for moderate complexity. Days to weeks for enterprise applications.
Best suited for: Small teams, simple applications, regulated environments where auditability is paramount, or situations where engineers are deeply familiar with the application under test.
2Level 2: Rules-Based Correlation Frameworks
What it looks like:
The tool ships with a library of predefined correlation rules, usually organised by web framework or technology. When you record against a .NET application, for example, the tool recognises known dynamic parameters like __VIEWSTATE, __EVENTVALIDATION, and ASP.NET session IDs, and applies preconfigured extraction rules automatically.
How it works in practice:
During or after recording, the tool scans requests and responses against its rule library. Each rule is essentially a template: "For applications using framework X, look for parameter Y in response Z, and extract using pattern P." The tool matches its templates against what it observes in the recorded traffic and applies correlations where it finds matches.
Leading commercial tools — including LoadRunner, BlazeMeter, NeoLoad, and OctoPerf — all implement some version of this approach. Some tools publish the specific web frameworks they support, effectively giving you a compatibility list. If your application's technology stack is on the list, you get a significant head start.
Where it works well:
Rules-based correlation is effective for well-known technology stacks with predictable dynamic data patterns. A standard Java Spring application with CSRF tokens, a .NET application with ViewState, or an OAuth 2.0 flow using standard grant types — these are exactly the scenarios rules-based engines were designed for. Industry reports suggest success rates of 60-90% for applications that closely match the rule library.
For organisations running standard commercial platforms and needing repeatable, predictable test preparation, this approach offers a solid middle ground between manual effort and automation. It's particularly useful when multiple testers work on similar application stacks, since the rules are consistent across team members.
Where it breaks down:
The limitation is inherent in the model: rules only work for patterns the vendor has already seen and codified. Custom application frameworks, bespoke authentication mechanisms, dynamically generated parameter names, or any technology not in the rule library will be missed entirely. The tester then falls back to manual correlation for everything the rules didn't catch, and diagnosing why a rule didn't fire (or fired incorrectly) can be more frustrating than doing it manually in the first place.
There's also a maintenance burden that's easy to overlook. Framework updates, new API versions, and evolving security patterns mean the rule library needs constant updating. If your vendor falls behind, or if you're an early adopter of a new framework, you're on your own.
Typical time investment: Significantly faster than manual for supported frameworks. Expect to handle 60-90% automatically on well-matched stacks, then spend manual effort on the remainder. The "last 10-40%" often represents the hardest, most time-consuming correlations.
Best suited for: Teams working with mainstream commercial platforms, organisations with predictable technology stacks, and environments where consistency across testers matters more than handling novel scenarios.
3Level 3: Code-Assisted Correlation Automation

What it looks like:
The tool uses algorithmic analysis — diffing engines, heuristic pattern matching, statistical anomaly detection — to identify dynamic values without relying on a predefined rule library. It compares multiple recordings or replays, spots values that change between executions, and generates extraction logic automatically.
How it works in practice:
Rather than matching against known frameworks, this approach compares a request parameter's value across two or more recordings of the same journey. If a value is identical across recordings, it's likely static. If it changes, it's a correlation candidate. The system then searches prior responses for the changed value's origin, applies smart algorithms to determine the best extraction method (regex, JSON path, XPath, boundary match), and inserts the correlation automatically.
More sophisticated implementations at this level add statistical scoring to rank correlation candidates by likelihood, use response structure analysis to narrow the search space, and apply encoding detection to handle Base64, URL encoding, or nested values. Some tools at this level are incorporating machine learning classifiers trained on historical correlation data to improve detection accuracy.
Where it works well:
This is the first level that's genuinely framework-agnostic. Because it doesn't rely on predefined rules, it can handle custom applications, bespoke frameworks, and novel authentication mechanisms. The algorithmic approach also scales better than manual work — doubling the number of correlation candidates doesn't double the analysis time in the same way it does for a human engineer.
For teams working across diverse technology stacks, or dealing with applications that don't fit neatly into a commercial tool's rule library, code-assisted automation is a meaningful step up. It's particularly valuable for API-heavy architectures where dynamic values appear in JSON payloads rather than traditional form parameters.
Where it breaks down:
The algorithms are smart, but they're not intelligent. They can tell you what changed, but they struggle with why it changed and whether it matters. False positives — flagging static values that happen to differ between recordings due to test data differences — require human review. False negatives — missing dynamic values that happen to look similar across recordings — cause failures that are difficult to diagnose.
Complex scenarios also challenge this approach. Values that are assembled client-side from multiple server responses, tokens that appear in encoded or encrypted form, values that are only dynamic under certain conditions, and cascading correlation chains (where extracting value A is a prerequisite for extracting value B) all require contextual understanding that pure algorithmic analysis lacks.
There's no learning between sessions, either. Each new script starts from scratch, which means the tool rediscovers patterns it has seen before and makes the same mistakes it made last time.
Typical time investment: Dramatically faster than manual for initial detection. Expect significant acceleration on first-pass correlation, but plan for a review and correction phase that can consume 20-40% of the total effort on complex applications.
Best suited for: Teams with diverse application landscapes, API-heavy architectures, organisations that have outgrown rules-based tools, and engineers who want automation assistance but are comfortable reviewing and adjusting the output.
4Level 4: AI-Driven Correlation (General-Purpose AI)

What it looks like:
Large language models (LLMs) and general-purpose AI are brought into the correlation workflow. Rather than relying purely on algorithmic pattern matching, the tool uses AI to understand the semantic meaning of requests and responses, reason about why a value might be dynamic, and generate extraction logic with contextual awareness.
How it works in practice:
The AI receives the recorded traffic — or more commonly, a structured representation of it — and analyses it with a level of comprehension that goes beyond pattern matching. It can read a JSON response and understand that "csrfToken": "abc123" is likely a security token that will change per session. It can trace authentication flows and understand that the Authorization header in request 47 should contain the bearer token returned in response 12. It can examine error messages from failed replays and reason about the probable cause.
Implementation typically involves integrating an LLM (such as GPT, Claude, or similar) into the performance testing tool's workflow — whether that's a JMeter AI plugin, a Locust AI assistant, or a standalone correlation service — either through API calls or embedded models. The AI may generate regex patterns, suggest JSONPath expressions, or even modify the script directly. Some implementations create a conversational interface where the engineer can ask the AI to "correlate the session token" or "fix the authentication flow."
Where it works well:
General-purpose AI brings genuine comprehension to the problem. It understands that an OAuth access_token and a custom x-auth-key serve similar functions, even though they look completely different. It can handle novel application architectures without predefined rules because it reasons from first principles rather than pattern libraries. For one-off or ad-hoc correlation tasks, especially when dealing with unfamiliar applications, this can be remarkably effective.
The conversational interface also lowers the barrier to entry. Junior engineers who struggle with regex syntax can describe what they need in plain language and get working extraction logic back. This is particularly valuable in teams with mixed skill levels.
Where it breaks down:
General-purpose AI wasn't built for this problem, and it shows in several ways.
First, context window limitations. A complex recording might contain thousands of requests and responses, each with headers, cookies, and body content. Feeding all of this into a general-purpose LLM either exceeds context limits or forces aggressive summarisation that loses critical detail. The AI might correctly identify that a token needs correlating but miss the specific response where it originated because that response was truncated or omitted.
Second, there's no accumulated knowledge. Each session starts fresh. The AI doesn't remember that last week it successfully correlated the same Salesforce aura_token pattern, or that a particular CDN's response headers always contain a specific dynamic value. It solves the same puzzle repeatedly, sometimes differently each time.
Third, general-purpose AI lacks the specialised understanding of performance test tooling that correlation demands. Generating a regex is one thing; generating a regex that is safe for JMeter's regex extractor (which has specific syntax requirements and boundary handling quirks) is another. An AI that suggests a perfectly valid regular expression which happens to use a lookahead unsupported by the target tool creates more debugging, not less.
Fourth, hallucination risk. LLMs occasionally generate plausible-looking but incorrect extraction logic — a JSONPath that references a non-existent field, or a regex that matches the right value in the example but also matches three other values in production. Without domain-specific validation, these errors propagate silently.
Typical time investment: Fast initial results but variable quality. Expect to spend significant time validating AI output, especially on complex applications. The "review and fix" phase can sometimes approach the time manual correlation would have taken, particularly when the AI's errors are subtle.
Best suited for: Teams already using AI tooling for other purposes, one-off correlation tasks on unfamiliar applications, and environments where the speed of a "good enough" first pass justifies the validation overhead.
5Level 5: Specialised AI with Domain-Enriched Intelligence

What it looks like:
A purpose-built system where specialised AI agents, enriched by deep domain knowledge of correlation patterns, work in concert with smart code to handle correlation end-to-end — detecting dynamic values, extracting them, substituting them, and validating the results. This is the direction LoadMagic is building toward, with key capabilities already in production and others actively in development.
How it works in practice:
The system operates on a fundamentally different model from the approaches described above. Rather than treating each correlation task in isolation, it combines specialised AI agents with deep domain understanding of how dynamic values behave across different technology stacks and application architectures.
When a new recording is imported, the system scans it for correlation candidates before the engineer even begins — identifying dynamic values, tracing where they originated in prior responses, and flagging which ones are likely to need extraction. Known noise domains (analytics, browser extensions, third-party trackers) are pre-excluded. Known encoding requirements are flagged. Known tricky patterns — like client-assembled values or multi-step token refresh chains — are highlighted with contextual guidance. Much of the analysis work is done before a single error is encountered.
For the actual correlation work, specialised AI agents analyse failures in context — not just "this request returned a 403" but "this request returned a 403 because the CSRF token in the request body doesn't match the one the server expects, and the server's expected value was returned in the response to request 23, in a JSON field at $.meta.csrfToken." The agents understand the full chain.
The agents themselves are specialised rather than general-purpose. A correlation agent identifies candidates and determines the extraction strategy. If the target value lives in a JSON response, it applies a JSONPath extractor directly. If a more complex boundary match is needed, it delegates to a regex specialist agent that builds expressions with proper boundaries and tool-safe syntax. A QA agent validates the result against best-practice standards. Each agent does what it's best at.
After successful correlation, the results feed back into the system. Patterns that work inform future sessions. When applications change — a platform update alters token locations or authentication flows — the system can detect the breakage and investigate, rather than leaving the engineer to start from scratch.
This is the self-healing dimension. If a previously working extractor breaks during a subsequent test run, the system doesn't just flag the error — it investigates. It identifies whether the failure is due to a changed response structure, a relocated value, a new encoding, or an entirely new dynamic parameter. It then proposes a fix: replacing the broken extractor, correcting a variable insertion, or re-correlating a value whose pattern has evolved. In LoadMagic, this self-healing pipeline is operational today for Locust scripts, with JMeter support actively in development.
Where it works well:
This approach is designed for the scenarios that defeat every other level: complex enterprise applications with dozens or hundreds of dynamic values, modern frameworks with bespoke authentication, applications that change frequently, and teams that need to maintain large portfolios of test scripts over time.
The specialised agents provide a significant advantage over general-purpose AI. Because they are purpose-built for correlation, they understand concepts like boundary-safe regex, tool-specific extractor syntax (JMeter's XPath vs Locust's Python), and the difference between a value that needs extraction and one that's static noise. A general-purpose LLM treats every request as a new problem. A specialised system brings domain expertise to every session.
For organisations where performance testing is a recurring, ongoing activity rather than a one-off event, the compounding effect is significant. Each session makes the platform smarter about the application under test, and that knowledge carries forward. What once took days of manual effort can be reduced to hours — with the gap widening as application complexity increases.
Where it breaks down:
This level of capability requires a specialised platform. You cannot replicate it by bolting a general-purpose LLM onto an existing tool. The agent orchestration, the self-healing pipeline, and the tool-safe code generation are all tightly integrated systems that need to be designed as a coherent whole.
There is also a trust curve. Engineers accustomed to manual control need to build confidence that the system's automated decisions are correct. Transparency — showing why a correlation was applied, where the evidence came from, and what the confidence level is — is essential for adoption, particularly in regulated environments.
Typical time investment: Hours rather than days or weeks for complex applications. Ongoing maintenance effort is significantly reduced as the self-healing pipeline handles routine drift.
Best suited for: Enterprise teams with large script portfolios, organisations testing complex commercial platforms, teams where performance testing is a continuous practice rather than a one-off activity, and environments where the cost of abandoned or outdated scripts outweighs the investment in specialised tooling.
Comparing the Five Levels
| Dimension | Level 1: AI-Assisted Manual | Level 2: Rules-Based | Level 3: Code-Assisted | Level 4: General AI | Level 5: Specialised AI |
|---|---|---|---|---|---|
| Detection method | Human-driven with AI hints | Template matching against known frameworks | Algorithmic diffing and heuristics | LLM semantic analysis | Specialised agents with domain knowledge |
| Framework dependency | None (but limited by engineer's knowledge) | High (vendor rule library) | Low (framework-agnostic algorithms) | None (but limited by context window) | None (framework-agnostic + accumulated knowledge) |
| Learning between sessions | Human memory only | None (static rule library) | None (starts fresh each time) | None (no persistent memory) | Continuous (domain knowledge compounds over sessions) |
| Self-healing capability | None | None | None | Limited (requires human re-prompting) | Automated (detects, investigates, proposes fixes) |
| Scalability | Poor (exponential effort growth) | Moderate (good for supported stacks) | Good (linear algorithmic scaling) | Variable (context window constrained) | Excellent (knowledge compounds over time) |
| Accuracy on novel apps | Depends on engineer skill | Poor (no matching rules) | Moderate (good detection, limited reasoning) | Good (but validation-heavy) | Very good (specialised agents + tool-safe code generation) |
| Typical success rate | 100% (eventually, with enough time) | 60-90% on matched stacks | 70-85% first pass | 60-80% (before validation) | High (improving with each session) |
| Cost profile | High recurring labour cost | Moderate licensing + labour for gaps | Moderate licensing + validation effort | API costs + validation labour | Platform investment, low recurring effort |
Choosing the Right Level for Your Context
There's no single "best" approach — only the best approach for your situation.
If you're a small team testing a handful of simple applications with stable architectures, Level 1 or Level 2 may be entirely sufficient. The investment in more sophisticated tooling doesn't pay back when you're correlating five values per script once a quarter.
If you work across a diverse set of technologies and need framework-agnostic detection but are comfortable with a review-and-adjust workflow, Level 3 gives you meaningful automation without platform lock-in.
If you're experimenting with AI across your engineering practice and want to extend that to performance testing, Level 4 can deliver quick wins — but go in with eyes open about the validation overhead and the absence of accumulated learning.
If performance testing is a core, ongoing practice for your organisation — if you maintain dozens or hundreds of scripts, if your applications change frequently, if correlation effort is a bottleneck that limits how much testing you can realistically do — then the compounding intelligence of Level 5 is where the economics start to shift. Specialised platforms that invest in this direction can deliver meaningful acceleration today, with the gap widening as the systems mature.
The trajectory of performance engineering is clear. Manual correlation is increasingly untenable as applications grow more complex. Rules-based approaches hit a ceiling that no amount of rule-writing can raise. General-purpose AI is powerful but unspecialised. The future of performance testing AI — whether applied to JMeter, Locust, or any other tool — lies in systems that combine deep domain expertise with specialised, purpose-built intelligence. Systems designed from the ground up for correlation, not adapted from general-purpose tools after the fact.

Read the full chapter — and 11 more
AI Performance Engineering is the practical field manual for AI-powered load testing, by David Campbell — founder of LoadMagic.