Why Correlation Needs Three Layers
Most correlation tools collapse observation, decision-making, and validation into a single step. That is why performance test scripts break. Here is the architecture that fixes it.
In our previous article on the correlation spectrum, we mapped five levels of correlation capability, from manual to specialised AI. That piece answered the question: what approaches exist?
This piece answers a different question: why do most of them break down as systems grow?
The answer is not about which technology you choose. It is about how many fundamentally different tasks you are asking one system to do at once.
The Single-Layer Trap
Every correlation approach, at every level of the spectrum, has to do three things:
- Observe what is happening in the traffic: which values are dynamic, where they originate, how they flow between requests.
- Decide what to do about it: which values need extraction, what type of extractor to use, where to place it, how it interacts with other correlations.
- Prove the decision was correct: run the test, check the results, confirm the extraction actually works at runtime.
Most tools collapse all three into a single operation. A rules engine scans the traffic, applies a template, and calls it done. A general-purpose AI reads the HAR file, generates extractors, and hopes for the best. A manual approach asks the engineer to observe, decide, and validate in one sitting.
A broken extractor might mean the pattern was wrong (bad observation), the extraction strategy was wrong (bad decision), or the application changed since the last run (invalid proof). Single-layer tools cannot distinguish between these failure modes. They just show you a red test result and leave you to figure out the rest.
Three Layers, Three Jobs
The alternative is to separate these concerns by design. Not as an implementation detail, but as an architectural principle. Each layer does what it is best at, trusts the others, and does not try to do their job.
Deterministic Measurement
The first layer is fast, cheap, exhaustive, and entirely mechanical. It scans every request and response. It identifies every value that changes. It records where each value first appeared and where it was reused. It detects patterns: this looks like a JWT, that looks like a CSRF token, this framework typically puts session IDs in this header.
What it does not do is decide anything. It does not say "this value needs an extractor." It does not say "use a JSON path, not a regex." It does not assign a confidence score. It reports what it observed and moves on.
This is the work that machines are unambiguously better at than humans. A scanner can check every value in every response against every subsequent request in milliseconds. A human doing the same work takes hours and misses things. There is no judgment required here, only thoroughness.
Intelligent Judgment
The second layer looks at the observations and makes decisions. This is where intelligence matters. Not all dynamic values need extraction. Some are static noise. Some are timestamps that change on every request but never need to be correlated. Some are session tokens that are critical to the entire flow.
The decision layer understands context that the observation layer cannot see: the purpose of the test, the structure of the application, the interaction between multiple dynamic values, the difference between a value that will break the test and one that is cosmetic.
This is the work that requires understanding, not just pattern matching. Whether the intelligence comes from a specialist AI agent or from a skilled performance engineer, the key property is the same: it produces a considered decision, not a mechanical output.
Critically, the decision layer has access to the observation layer's complete output. It does not need to re-scan the traffic. It does not need to rediscover which values are dynamic. It focuses entirely on what matters: what to correlate, how, and why.
Runtime Validation
The third layer runs the test and checks what actually happened. Did the extractor capture the right value? Did the substitution work? Did the server accept the request? This is not a theoretical check. It is ground truth from a real execution.
When the proof succeeds, the decision becomes trusted. The system now knows, with evidence, that this particular extraction strategy works for this particular application in its current state. That evidence can be stored, versioned, and used as a baseline for future comparisons.
When the proof fails, the system knows exactly what to investigate. Was the observation wrong (the value was not where the scanner said it was)? Was the decision wrong (the extraction strategy does not fit this type of value)? Or has the application changed (the value moved, the format changed, the endpoint was restructured)?
Each failure mode has a different resolution path. A three-layer system can distinguish between them. A single-layer system cannot.
Why This Matters for Self-Healing
Self-healing is the promise every correlation tool eventually makes: when the application changes, the tests adapt. But self-healing only works if you can diagnose what changed and why.
In a single-layer system, a test failure is just a failure. You re-run the correlation process and hope the new output is better than the old one. There is no concept of "the extraction strategy was correct but the application moved the value to a different field." There is no concept of "the observation was accurate but the decision was wrong for this framework." Everything is a black box re-run.
In a three-layer system, self-healing becomes diagnostic. The observation layer can re-scan and report what changed in the traffic. The decision layer can compare the new observations against the previous decision and determine if the strategy still applies or needs revision. The proof layer can confirm the repair worked.
Why This Matters for Scale
At small scale, the difference between one layer and three is invisible. If you are correlating five values in a simple application, any approach works. You can observe, decide, and validate in your head in a single pass.
At enterprise scale, with dozens or hundreds of dynamic values across complex applications that change frequently, the single-layer model collapses. You cannot hold the full observation in your head. You cannot make consistent decisions across hundreds of values. You cannot validate everything manually after every change.
Three layers scale independently:
- Observation scales mechanically. Scanning a thousand values takes the same architecture as scanning ten. The observation layer is embarrassingly parallel.
- Judgment scales with intelligence. Whether that intelligence is human, AI, or a combination, the decision layer only needs to handle the values that actually require decisions. The observation layer has already filtered the noise.
- Proof scales with automation. Running a test and checking results is a pipeline problem, not an intelligence problem. It can run continuously.
The Compounding Effect
The most powerful property of a three-layer system is that it learns. Each layer produces outputs that improve the next cycle:
- The observation layer builds a comprehensive map of every dynamic value in the application. Over time, it develops a world view: a complete picture of how data flows through the system.
- The decision layer accumulates proven strategies. When a decision has been validated by the proof layer, it becomes part of the system's memory. Next time a similar value appears, the system already knows what works.
- The proof layer builds a golden baseline: a set of validated extraction strategies that represents the known-good state of the application. Drift from this baseline is automatically detected and investigated.
This is the compounding intelligence we described in Level 5 of the correlation spectrum. It is not magic. It is a consequence of keeping observation, judgment, and validation separate so that each can evolve independently and feed the others.
How LoadMagic Implements This
LoadMagic's architecture is built around this separation. When a recording is imported, the observation layer scans it exhaustively: identifying dynamic values, tracing their origins, detecting framework signatures, and building a complete map of correlation candidates. This happens in seconds, with no AI cost, and produces the raw material for everything that follows.
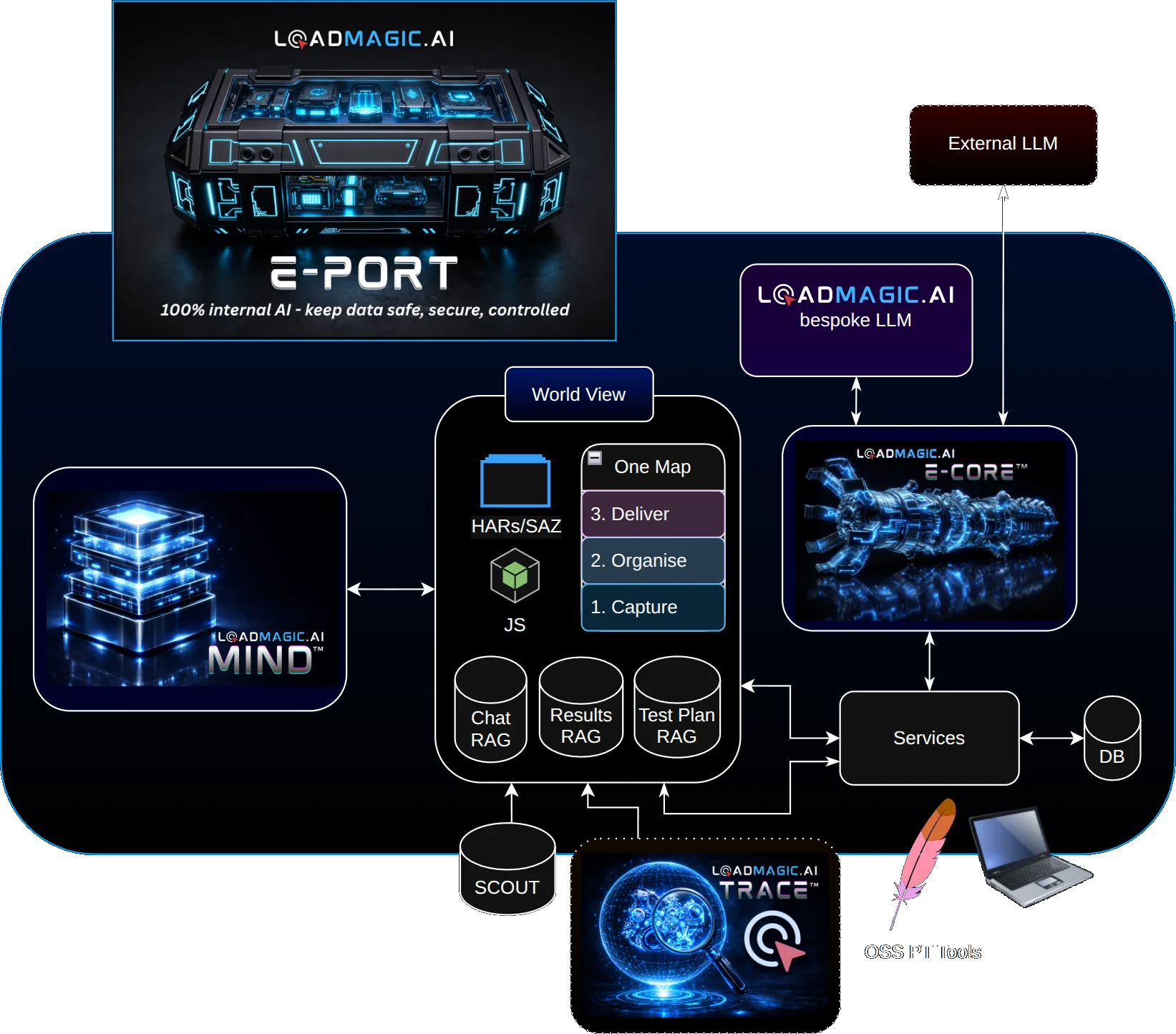
The intelligence layer, powered by specialised AI agents within our E-CORE engine, then evaluates these observations. Each agent is purpose-built for a specific type of correlation decision. They understand tool-specific syntax, framework-specific patterns, and the difference between a value that needs correlation and one that does not. Their decisions are informed by MIND, our knowledge system, which carries forward what has worked in previous sessions.
The validation layer runs the tests, checks the results, and builds the golden baseline. When something breaks, the system does not just re-run. It diagnoses: the observation layer shows what changed in the traffic, the intelligence layer determines whether the original strategy still applies, and the validation layer confirms the repair. This is what makes self-healing reliable rather than hopeful.
The World View, at the centre of our architecture, is where all three layers converge. It is the living, evolving map of how an application's dynamic data behaves. It grows with every import, every test run, every repair. And it is the foundation for where we are heading next: a specialised correlation model trained on real-world performance testing data, built to understand correlation at a level that no general-purpose AI can match.
The Question to Ask Your Tooling
Whatever correlation approach you use today, ask this question: when a test breaks, can the system tell you whether the observation was wrong, the decision was wrong, or the application changed?
If the answer is no, you are working with a single-layer tool. It may work well at small scale. But as your applications grow, as your test portfolios expand, as the pace of change accelerates, you will spend more and more time on the diagnostic work that three layers handle by design.
The future of correlation is not better pattern matching, and it is not bigger language models. It is the right architecture: measurement where measurement belongs, judgment where judgment belongs, and proof that closes the loop.

The whole architecture, in one book
Chapter 3 is where the three-layer model earns its keep. The rest of AI Performance Engineering shows it running in production.